NVCCを使ったコンパイル¶
カーネルはPTXと呼ばれる、CUDAの命令セットを使って書くこともできる。しかし、普通はC++のような高級言語を使ったほうがより効率的である。どちらにしろ、カーネルはnvccを使ってデバイス上で実行されるバイナリコードにコンパイルされる必要がある。
nvccはC++やPTXコードのコンパイルを単純にするコンパイルドライバーである。これは単純で親しみ深いコマンドを提供し、異なるコンパイルステージを実装するツールを呼び出して実行する。この節ではnvccワークフローの概要とコマンドオプションの概要を述べる。
詳しくはNVIDIA CUDA Compiler Driver NVCCにて。
コンパイルワークフロー¶
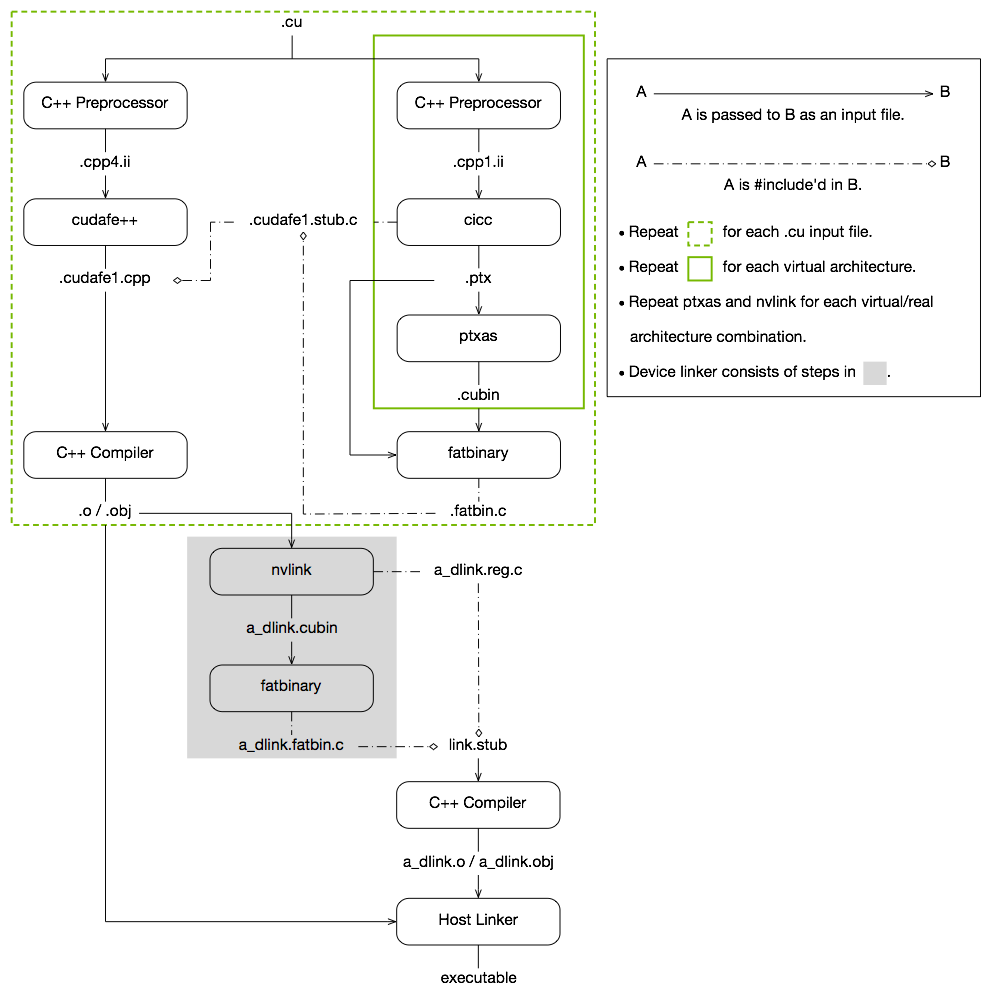
オフラインコンパイル¶
nvccによってコンパイルされるソースファイルはホストコードとデバイスコードを含みうる。nvccの基本的なワークフローは
- ホストコードからデバイスコードを分け、
- デバイスコードをアセンブリ形式(PTXコード)かバイナリ形式(cubinオブジェクト)にコンパイルし、
- ホストコードでカーネルに指定された
<<<...>>>を、PTXコードやcubinオブジェクトからコンパイルされたカーネルを読み込んで起動するために必要なCUDAランタイム関数の呼び出しに置き換える
ことである。
修正されたホストコードは他のツールを使ってコンパイルできるようにC++コードとして出力されるか、最後のコンパイルステージでnvccにホストコンパイラを呼び出させることでオブジェクトコードとして直接出力される。
アプリケーションは、
- コンパイルされたホストコードをリンクするか、
- 修正されたホストコードを無視して、PTXコードかcubinオブジェクトをロードし、実行するためにCUDAドライバーAPIを使う (詳しくはドライバーAPIにて)。
Just-in-Timeコンパイル¶
実行時にアプリケーションにロードされるPTXコードは、デバイスドライバーによってバイナリコードにコンパイルされる。これはjust-in-timeコンパイルと呼ばれる。just-in-timeコンパイルはアプリケーションのロードタイムを増やすが、アプリケーションが新しいコンパイラーの改善を享受できるようになる。また、この方法はアプリケーションがコンパイルされた時に存在しなかったデバイス上で実行するための唯一の方法である。詳しくはアプリケーション互換性にて。
デバイスドライバーはアプリケーションのPTXコードをjust-in-timeコンパイルする時、アプリケーションの呼び出し毎にコンパイルしないように、生成したバイナリコードのコピーを自動的にキャッシュする。(compute cacheと呼ばれる)このキャッシュはデバイスドライバーがアップグレードされた時に自動的に無効になるので、アプリケーションはデバイスドライバーに組み込まれた新しいjust-in-timeコンパイラーの改善を享受することが出来る。
環境変数を使うと、just-in-timeコンパイルをコントロールできる。詳しくはCUDAの環境変数にて。
CUDA C++デバイスコードをコンパイルするためにnvccを使う代わりとして、実行時にCUDA C++デバイスコードをPTXにコンパイルするNVRTCを使うことが出来る。NVRTCはCUDA C++の実行時コンパイルライブラリである。
バイナリ互換性¶
バイナリコードはアーキテクチャ特有である。cubinオブジェクトは対象アーキテクチャを指定するコンパイラーオプション-codeを使って生成される。例えば、-code=sm_80を付けてコンパイルすると、compute capability 8.0のデバイスに対するバイナリコードが作られる。compute capability X.yに対して生成されたcubinオブジェクトはcompute capability X.z(z>=y)のデバイス上でしか実行できない。
注
バイナリ互換性はデスクトップのみサポートする。Tegraに対してはサポートされず、デスクトップとTegra間のバイナリ互換性もサポートされない。
PTX互換性¶
いくつかのPTX命令は高いcompute capabilityを持つデバイス上でしかサポートされない。例えば、warpシャッフル関数はcompute capabilityが5.0以上のデバイス上でしかサポートされない。-archコンパイラーオプションにはC++をPTXコードにコンパイルする時に必要なcompute capabilityを指定する。例えば、warpシャッフルを含むコードは-arch=compute_50(かそれ以上)を付けてコンパイルされなければならない。
ある特定のcompute capabilityに対して作られたPTXコードは必ずそれ以上のcompute capabilityを持つバイナリコードにコンパイルされる。以前のPTXのバージョンからコンパイルされたバイナリはいくつかのハードウェアの特徴を利用しないかもしれないので、最終的なバイナリは最新のPTXを使って生成されたバイナリより性能が悪いかもしれない。
compute capabilityは仮想アーキテクチャとも呼ばれ、プリプロセスとPTXへのコンパイルをコントロールするために使われる。そのため、-archオプションだけを指定しても実行ファイルやライブラリを作れず、-codeオプションで物理アーキテクチャを指定しなければならない。
アプリケーション互換性¶
特定のcompute capabilityのデバイス上でコードを実行するためには、アプリケーションはこのcompute capabilityと互換性のあるバイナリかPTXコードをロードしなければならない。特に、高いcompute capabilityを持つ、将来のアーキテクチャ上でコードを実行できるようにするためには、アプリケーションはこれらのデバイスに対してjust-in-timeでコンパイルされるPTXコードをロードしなければならない。
どのPTXとバイナリコードがCUDA C++アプリケーションに埋め込まれるかはコンパイルオプション-archと-codeまたはgencodeによって制御される。例えば、
nvcc x.cu
-gencode arch=compute_50,code=sm_50
-gencode arch=compute_60,code=sm_60
-gencode arch=compute_70,code=\"compute_70,sm_70\"
とすると、最初と2番目の-gencodeオプションからcompute capability 5.0と6.0に互換性があるバイナリコードと、3番目の-gencodeオプションからcompute capability 7.0と互換性があるPTXとバイナリコードを埋め込む。
ホストコードは実行時に最も適したコードを自動的に選ぶよう生成される。上の例では以下のようになる。
- compute capability 5.0と5.2を持つデバイスに対する5.0バイナリコード
- compute capability 6.0と6.1を持つデバイスに対する6.0バイナリコード
- compute capability 7.0と7.5を持つデバイスに対する7.0バイナリコード
- compute capabilityが8.0以上のデバイスに対する、実行時にバイナリコードにコンパイルされるPTXコード
compute capabilityに基づいた様々なコードパスを区別するために__CUDA_ARCH__マクロを使うことが出来る。ただし、このマクロはデバイスコードでのみ定義されている。例えば、-arch=compute_80を付けてコンパイルするとき、__CUDA_ARCH__の値は800である。
ドライバーAPIを使うアプリケーションは実行時に最適なコードを明示的にロードし実行できるようにコンパイルしなければならない。
例えば、VoltaアーキテクチャはスレッドがGPU上でスケジュールされる方法を変えるIndependent Thread Schedulingを導入しているが、以前のアーキテクチャ内のSIMTスケジューリングの特定の振る舞いに依存するコードに対して、Independent Thread Schedulingは関係するスレッドの集合を変えるかもしれず、不正確な結果をもたらす。
Independent Thread Schedulingを実装しつつ移植するためには、Volta開発者はコンパイルオプション-arch=compute_60 -code=sm_70をつけてPascalのスレッドスケジューリングに最適化すればよい。
nvccユーザーマニュアルは-arch、-code、-gencodeコンパイラーオプションに対する様々な短縮形をリストにまとめている。例えば、-arch=sm_70は-arch=compute_70 -code=compute_70,sm_70の略である。
C++互換性¶
コンパイラのフロントエンドはCUDAソースファイルをC++の文法に従って処理する。全てのC++の機能はホストコードに対してはサポートされるが、デバイスコードに対しては一部のみサポートされる。詳しくはC++言語サポートにて。
64ビット互換性¶
64bitバージョンのnvccは64bitモード(つまりポインターが64bit)でデバイスコードをコンパイルする。64bitモードでコンパイルされたデバイスコードは64bitモードでコンパイルされたホストコードでしかサポートされない。