プログラミングモデル¶
この章では、CUDAプログラミングモデルの背後にある主な概念を紹介する。 詳細は、プログラミングインターフェイスにて。 この章で使われる、ベクトル加算のソースコードはここにある。
カーネル¶
CUDA C++は、プログラマーがカーネルと呼ばれる関数を定義できるようにC++を拡張している。カーネルは呼び出された時、普通の関数が1度しか実行されないのに対して、N個のCUDAスレッドによって並列にN回実行される。
カーネルは__global__宣言指定子を使って定義され、カーネル呼び出しに対してそのカーネルを実行するCUDAスレッドの数は新しい実行設定構文<<<...>>>を使って指定される (詳しくはC++の拡張にて)。カーネルを実行する各スレッドは組み込み変数を通してカーネル内で使える一意なスレッドIDを与えられる。
例として、組み込み変数threadIdxを使う以下のサンプルコードはサイズがNの2つのベクトルAとBを足し、結果をベクトルCに入れる。
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
ここで、VecAdd()を実行するN個のスレッドは要素毎の足し算を行う。
スレッド階層¶
便利なため、threadIdxは3次元のベクトルとしている。結果として、スレッドは1次元、2次元、3次元のスレッドインデックスを使って識別され、スレッドブロックと呼ばれるスレッドの1次元、2次元、3次元のブロックを形成する。
スレッドのインデックスとそのスレッドIDは以下の表のように関係している。
| ブロックサイズ | スレッドインデックス | スレッドID |
|---|---|---|
| (Dx) | (x) | x |
| (Dx, Dy) | (x, y) | x + y * Dx |
| (Dx, Dy, Dz) | (x, y, z) | x + y * Dx + z * Dx * Dy |
例として、以下のコードはサイズがN * Nの2つの行列を足して、結果を行列Cに入れる。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
ブロックのすべてのスレッドは同じストリーミングマルチプロセッサー上にあると期待されていて、そのコアの限られたメモリを共有しなければならないため、ブロックあたりのスレッド数には制限がある。現在のGPUでは、スレッドブロックの最大スレッド数は1024である。
カーネルは複数の同じ形のスレッドブロックによって実行されるため、スレッドの総数は(ブロックあたりのスレッド数) x (ブロック数)と等しい。
ブロックは以下の図のように、スレッドのブロックの1次元、2次元、3次元のグリッドに統合されている。
 スレッドブロックのグリッド
スレッドブロックのグリッド
<<<...>>>で指定された、ブロックあたりのスレッド数とグリッドあたりのブロック数の型はintまたはdim3である。2次元のブロックまたはグリッドは上の例で指定されている。
グリッド内の各ブロックは組み込み変数blockIdxを通してカーネル内でアクセスできる、1次元、2次元、3次元の一意なインデックスによって識別される。スレッドブロックの次元は組み込み変数blockDimを通してカーネル内でアクセスできる。
前のMatAdd()の例を複数のブロックを扱うよう拡張すると、コードは以下のようになる。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
(この場合は任意だが) 16 * 16 個のスレッドブロックはよくある選択である。このグリッドは以前のように行列の要素あたり1つのスレッドを持つのに十分なブロックと一緒に作られている。単純にするために、この例では各次元のグリッドあたりのスレッド数はその次元のブロックあたりのスレッド数で割れると仮定しているが、その必要はない。
後述のスレッドブロッククラスターを使わない場合、スレッドブロックは順不同で、並列または逐次的に実行できなければならない。
ブロック内のスレッドは__syncthreads()という関数を使うと同期できる。つまり、ブロック内の各スレッドはブロック内の全てのスレッドが__syncthreads()を実行するまで待たなければならない。
共有メモリには共有メモリを使った例があり、Cooperative Groups APIには同期するスレッドを管理するAPIが書かれている。
スレッドブロッククラスター¶
Compute Capability 9.0からスレッドブロッククラスターという、スレッドブロックから構成された、省略可能なスレッド階層が導入された。クラスターでは、複数のストリーミングマルチプロセッサーで並列に動作する複数のスレッドブロックを同期させ、共同でデータの取得や交換を行うことができる1。スレッドブロックと同様に、クラスターも1次元または2次元、3次元で構成されている。クラスター内のスレッドブロック数はユーザーが決められ、ポータブルなクラスターサイズとして最大8スレッドブロックがサポートされている。cudaOccupancyMaxPotentialClusterSize関数で確認することも出来る。
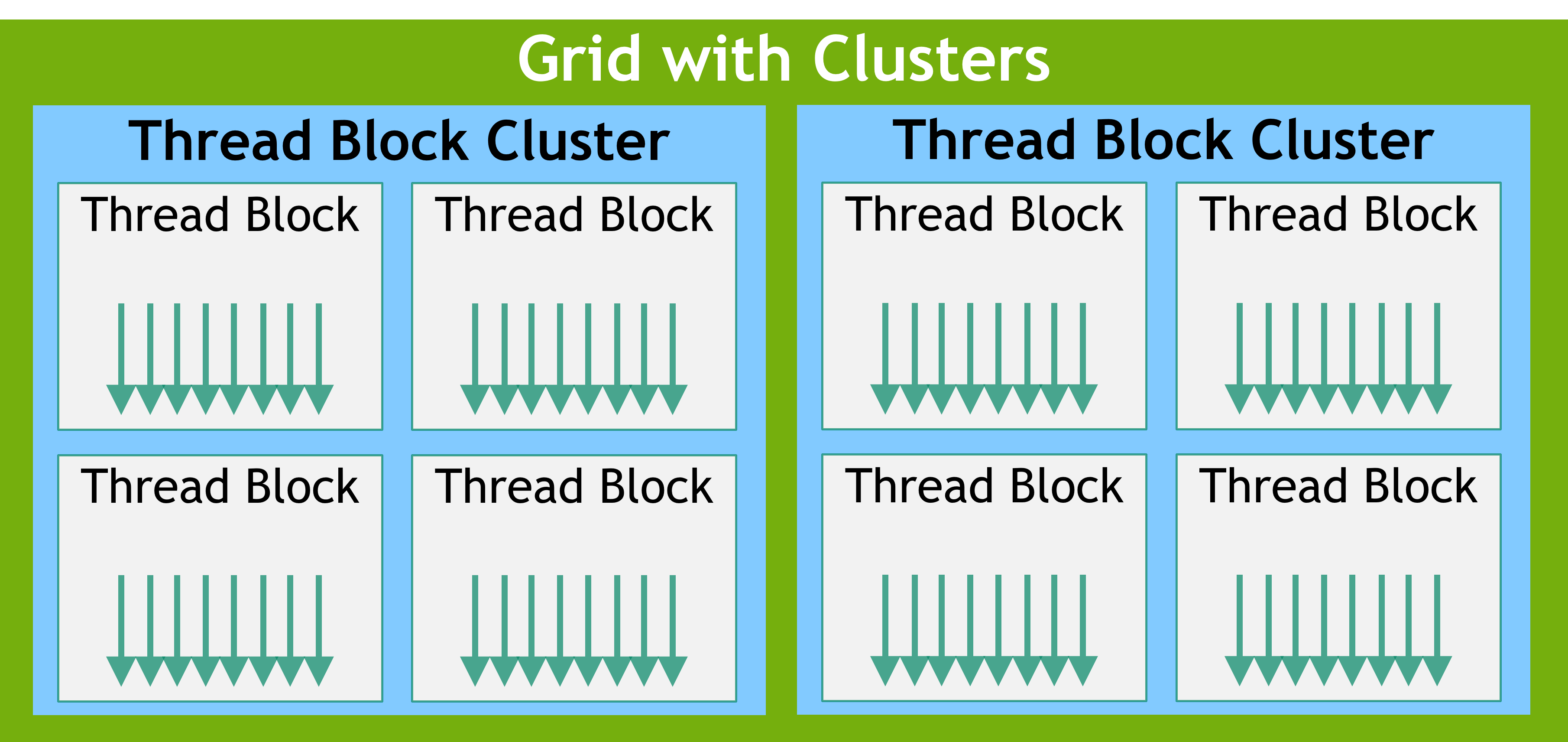 スレッドブロッククラスターのグリッド
スレッドブロッククラスターのグリッド
注
互換性から、gridDim変数はスレッドブロック数の意味でのサイズを表している。クラスター内のブロックのランクはクラスターグループAPIを使うと得られる。
スレッドブロッククラスターは__cluster_dims__(X,Y,Z)というカーネル属性を使ってコンパイル時に有効にしたり、cudaLaunchKernelExというCUDAカーネルを実行する関数を使って実行時に有効にしたり出来る。
以下はコンパイル時カーネル属性を使った、クラスターの使い方の例である。 コンパイル時にクラスターサイズを指定すると、カーネル起動時にクラスターサイズを変更できない。
// Kernel definition
// Compile time cluster size 2 in X-dimension and 1 in Y and Z dimension
__global__ void __cluster_dims__(2, 1, 1) cluster_kernel(float *input, float* output)
{
}
int main()
{
float *input, *output;
// Kernel invocation with compile time cluster size
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// The grid dimension is not affected by cluster launch, and is still enumerated
// using number of blocks.
// The grid dimension must be a multiple of cluster size.
cluster_kernel<<<numBlocks, threadsPerBlock>>>(input, output);
}
また、以下は実行時にクラスターサイズを指定する例である。
// Kernel definition
// No compile time attribute attached to the kernel
__global__ void cluster_kernel(float *input, float* output)
{
}
int main()
{
float *input, *output;
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// Kernel invocation with runtime cluster size
{
cudaLaunchConfig_t config = {0};
// The grid dimension is not affected by cluster launch, and is still enumerated
// using number of blocks.
// The grid dimension should be a multiple of cluster size.
config.gridDim = numBlocks;
config.blockDim = threadsPerBlock;
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeClusterDimension;
attribute[0].val.clusterDim.x = 2; // Cluster size in X-dimension
attribute[0].val.clusterDim.y = 1;
attribute[0].val.clusterDim.z = 1;
config.attrs = attribute;
config.numAttrs = 1;
cudaLaunchKernelEx(&config, cluster_kernel, input, output);
}
}
スレッドブロッククラスターを使うと、クラスター内のスレッドブロックは全て一緒にスケジュールされ、クラスターグループAPIのcluster.sync()を使って同期できる。また、クラスターグループはスレッド数やブロック数の意味でクラスターグループのサイズを得るnum_thread()やnum_blocks()といったメンバ関数を提供している。
クラスター内のスレッドブロックは分散共有メモリへの読み書きと排他制御を行える。分散共有メモリには分散共有メモリでヒストグラムを計算する例が載っている。
メモリ階層¶
CUDAスレッドは以下の図のように、実行中に複数のメモリ空間のデータにアクセスできる。
- 各スレッドはプライベートなローカルメモリを持つ。
- 各スレッドブロックはブロック内のスレッドからアクセスできる、ブロックと同じ生存期間を持つ共有メモリを持つ。
- スレッドブロッククラスター内のスレッドブロックはお互いの共有メモリへの読み書きと排他制御を行える。
- すべてのスレッドは同じグローバルメモリにアクセスできる。
また、定数とテクスチャメモリ空間は全てのスレッドからアクセスできる、読み込み専用メモリである。グローバル、定数、テクスチャメモリ空間は異なるメモリ使用法に対して最適化されている (詳しくはデバイスメモリアクセスにて)。テクスチャメモリは特定のデータフォーマットに対して異なるアドレッシングモードとデータフィルタリングも提供している (詳しくはテクスチャとサーフェスメモリにて)。
グローバル、定数、テクスチャメモリ空間は同じアプリケーションによるカーネルの実行中、持続する。
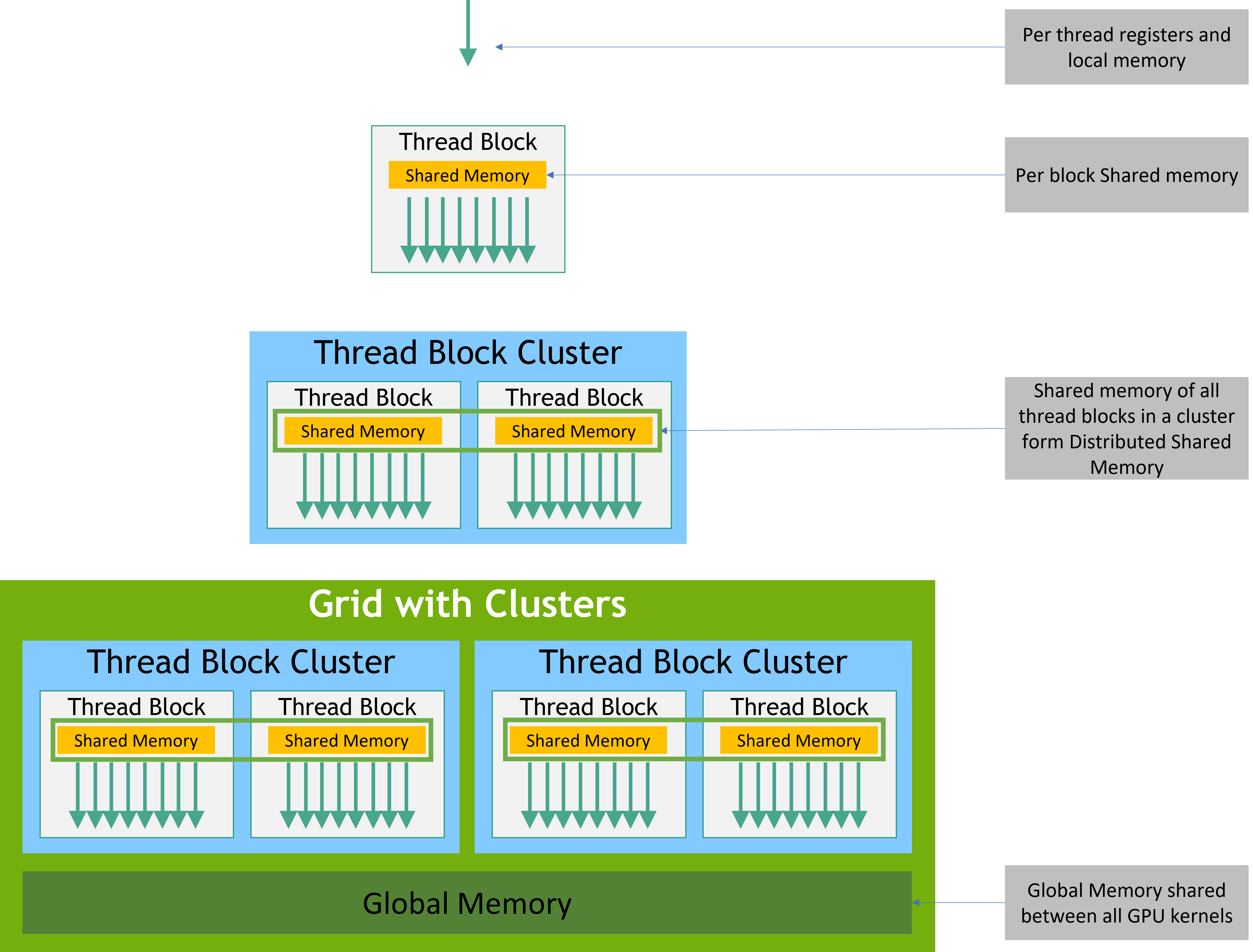 メモリ階層
メモリ階層
ヘテロジニアスプログラミング¶
以下の図に示すように、CUDAのプログラミングモデルはCUDAスレッドが物理的に分けられた、ホストに付随するデバイス上で実行されることを仮定している。これは例えば、カーネルがGPU上で実行されていて、CPU上でC++プログラムの残りを実行する時である。
CUDAプログラミングモデルはホストとデバイスの両方がそれぞれ自身のメモリ空間をDRAMの中に持つことも仮定している。これらのメモリはそれぞれホストメモリとデバイスメモリと言われる。従って、プログラムはCUDAランタイムの呼び出しを通して、カーネルからアクセスできるグローバル、定数、テクスチャのメモリ空間を管理する (詳しくはプログラミングインターフェイスにて)。これはデバイスメモリの確保と解放、ホストとデバイスメモリ間のデータ転送も含む。
ユニファイドメモリと呼ばれる、ホストとデバイスの両方からアクセスできる、単一のメモリアドレス空間もある。このメモリを使うと、CPUとGPUの両方からアクセスされるデータのメモリ確保やアクセスがとても簡単になる。詳しくはユニファイドメモリプログラミングにて。
 ヘテロジニアスプログラミング
ヘテロジニアスプログラミング
非同期SIMTプログラミングモデル¶
CUDAのプログラミングモデルでは、スレッドは計算やメモリ操作を行う最も低レベルな抽象化である。compute capability 8.0以上のデバイスでは、ハードウェアによる高速なバリアやメモリコピーが提供されている。compute capability 7.0以上が必要。
非同期操作¶
非同期操作はCUDAスレッドによって開始される操作として定義され、まるで他のスレッドによって行われるように非同期に実行される。正しいプログラムでは、一つ以上のCUDAスレッドが非同期操作と同期する。非同期操作を開始したCUDAスレッドは同期しているスレッドに含まれる必要はない。
非同期なスレッドは必ず非同期操作を開始したCUDAスレッドに紐付いている。非同期操作は操作の完了を同期するために同期オブジェクトを使う。同期オブジェクトは(例えばcuda::memcpy_asyncなどで)明示的にユーザーによって管理されるか、(例えばcooperative_groups::memcpy_asyncなどで)暗黙にライブラリによって管理される。同期オブジェクトの例として、cuda::barrierやcuda::pipelineがある。詳しくは非同期バリアとcuda::pipelineを使った非同期なデータコピーにて。
これらの同期オブジェクトは異なるスレッドスコープで使うことが出来る。スコープは非同期操作と同期するための同期オブジェクトを使うかもしれないスレッドの集合を定義する。 以下のテーブルはCUDA C++で使えるスレッドスコープと一緒に同期されるスレッドを定義する。
| スレッドスコープ | 同期対象のCUDAスレッド |
|---|---|
cuda::thread_scope::thread_scope_thread |
非同期操作を開始したスレッドのみ |
cuda::thread_scope::thread_scope_block |
開始したスレッドと同じスレッドブロック内の任意のスレッド |
cuda::thread_scope::thread_scope_device |
開始したスレッドと同じGPUデバイス内の任意のスレッド |
cuda::thread_scope::thread_scope_system |
開始したスレッドと同じシステム内の任意のスレッド |
これらのスレッドスコープはCUDA標準C++ライブラリ内の標準C++の拡張として定義されている。
Compute Capability¶
デバイスのCompute Capabilityは時々、"ストリーミングマルチプロセッサーバージョン"(SMバージョン)とも呼ばれる、バージョン番号によって表される。このバージョン番号はGPUハードウェアによってサポートされる特徴を識別し、現在のGPU上でどのハードウェアの特徴や命令が使えるかを決定するために実行時にアプリケーションによって使われる。
compute capabilityはメジャーバージョンXとマイナーバージョンYからなり、X.Yと表される。同じメジャーバージョンを持つデバイスは同じコアアーキテクチャを持つ。マイナーバージョンは新しい特徴やコアアーキテクチャの改善に対応する。